At Misfits Market we recently moved from a combination of a self hosted Prometheus/Loki/Grafana setup, along with some other external tools to Datadog as our all in one monitoring platform.
While Datadog offers 500+ builtin integrations, there will be the occasional service that you use that won’t be covered. Luckily it is fairly easy to write a custom agent check (or even a full on integration).
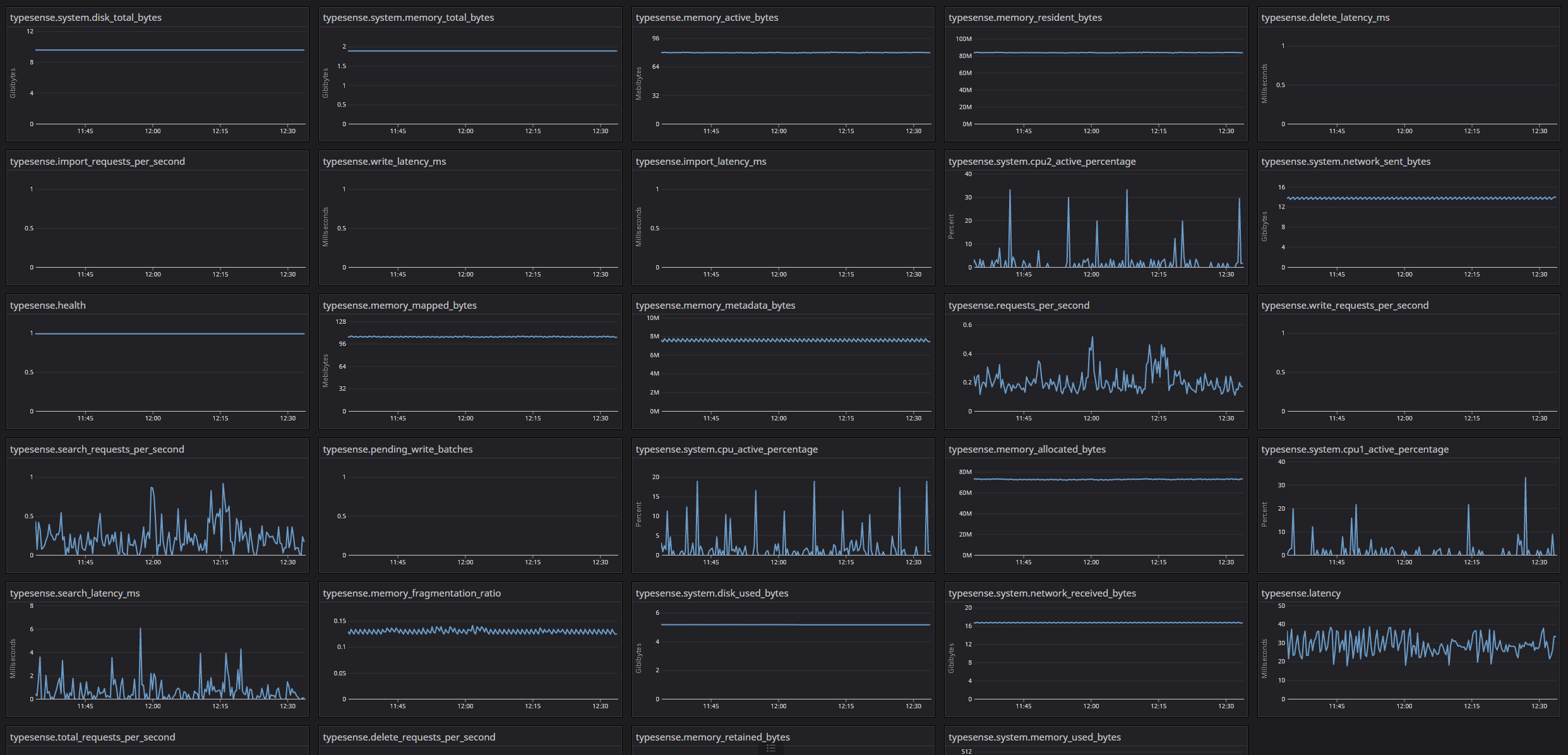
One integration we were missing was for our search engine Typesense. So I put together a quick custom agent check. I would like to possibly write an actual integration for it someday but I just wanted to get something off the ground quickly.
You can find it on Github here.
Install
Check Location
Upload the check script typesense.py to /etc/datadog/checks.d/typesense.py.
Configure
Create a configuration file located at /etc/datadog/conf.d/typesense.yaml. Check typesense.yaml in the repo as an example.
Screenshot